GPT-3: um algoritmo de machine learning que consegue escrever textos
“As máquinas conseguem entender e gerar textos humanos?” é uma pergunta que não é nova. As primeiras tentativas de respondê-la vêm da década de 50 [1], com a aplicação de métodos estatísticos para recuperar informações de um texto. Desde então, este campo, que é chamado de NLP (Natural Language Processing, ou Processamento de Linguagem Natural) tem avançado muito, com novas técnicas de machine learning sendo aplicadas. Ainda segundo [1], um algoritmo de machine learning infere padrões a partir dos dados de treinamento, e então consegue generalizar para dados que ele não conhece. Para obter tais resultados e garantir uma boa acurácia, é necessária uma quantidade adequada de exemplos de treinamento. Talvez o maior exemplo de machine learning aplicada ao NLP seja o IBM Watson [2]. Porém, diversos outros projetos existem e um deles tem ganhado bastante notoriedade. É o GPT-3 (Generative Pre-training Transformer 3), desenvolvido pela OpenAI. O nível atingido por este projeto é tão alto que, segundo o Gizmodo, ele respondeu perguntas no Reddit por uma semana até ser identificado e banido.
No artigo submetido pelos autores do projeto [3], eles explicam que o GPT-3 foi treinado com 175 bilhões de parâmetros, e teve o desempenho verificado sob as seguintes condições: zero-shot, one-shot e few-shots. A diferença, conforme explicitado na imagem abaixo, é que sob a condição zero-shot somente a descrição do problema era fornecida (por exemplo, “Traduzir português para inglês”). Na one-shot, um exemplo de solução era fornecido (por exemplo, “melancia = watermelon”), enquanto na few-shots, algumas soluções eram dadas.
Para treinar a rede neural, foram utilizadas alguns datasets, incluindo verbetes da Wikipedia, totalizando aproximadamente 500 bilhões de tokens. Para validar o modelo, diversos testes foram executados, incluindo o LAMBADA [4], que requer que a última palavra do parágrafo seja adivinhada, levando em consideração as informações contidas naquele parágrafo. Os resultados do GPT-3 são demonstrados a seguir:
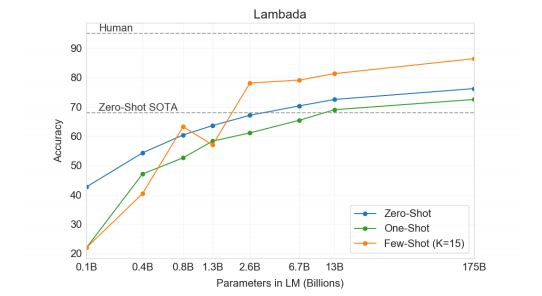
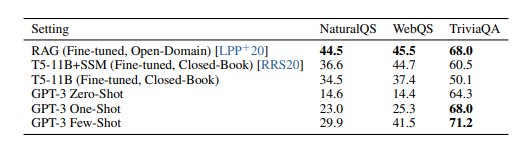
Diversos outros testes foram realizados, como de tradução de textos e respostas a perguntas. Neste, o GPT-3 também demonstrou uma evolução em relação a outros métodos (na tabela, quanto maior o número, melhor o desempenho):
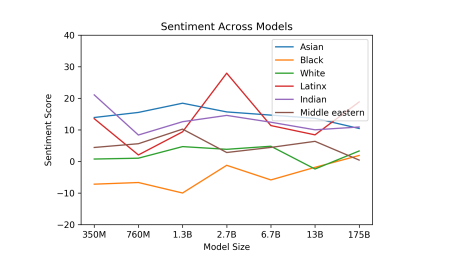
Assim, percebe-se que o estado-da-arte em NLP está avançando rapidamente. Porém, conforme os textos vão ficando cada vez mais “naturais”, no sentido de que parecem ter sido escritos por um humano, algumas ressalvas precisam ser feitas. Um exemplo elencado pelos autores é que essa geração automática pode ser utilizada para fins ilícitos ou imorais, como tentativas de phishing (se passando por alguma autoridade, por exemplo), ou escrita de artigos científicos fraudulentos. Outro ponto levantado, e que já é discutido pela comunidade acadêmica, é sobre vieses embutidos nos dados de treinamento. Para verificar a existência destes, foram ponderadas análises de sentimentos sobre raças, o que indicou a existência de sentimentos positivos relacionados a “asiáticos”, enquanto “negros” carregavam uma conotação mais negativa. Os autores alertam que são necessários estudos mais aprofundados para garantir que esses vieses sejam mitigados pelas redes neurais.
Por fim, nota-se que o GPT-3 é uma rede neural muito robusta para análise de linguagem natural. Seus textos estão se tornando cada vez mais elaborados e consistentes. Se, por um lado, isso apresenta diversas aplicações positivas (como tradução simultânea automatizada, criação de legendas automatizadas, etc.), por outro, é necessário um esforço cada vez maior para evitar que os algoritmos reproduzam comportamentos considerados inadequados, bem como evitar que aplicações fraudulentas passem despercebidas.
Referências:
[1] NADKARNI, Prakash M.; OHNO-MACHADO, Lucila; CHAPMAN, Wendy W. Natural language processing: an introduction. Journal of the American Medical Informatics Association, v. 18, n. 5, p. 544-551, 2011.
[2] IBM Watson. Disponível em: https://www.ibm.com/watson/br-pt/.
[3] B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan,P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan,R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Si-gler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford,I. Sutskever, and D. Amodei, “Language models are few-shot learners,” 2020. Disponível em: https://arxiv.org/abs/2005.14165.
[4] Paperno, G. Kruszewski, A. Lazaridou, Q. N. Pham, R. Bernardi, S. Pezzelle, M. Ba-roni, G. Boleda, and R. Fernández, “The lambada dataset: Word prediction requiringa broad discourse context,” 2016.


